
Clean Architectureは息苦しくない
概要
Clean Architectureでサービスを運用して1年近く経ちました。
チームのメンバーからより良くなる提案をしてもらい、アーキテクチャ自体は走りながら一部リアーキされたので個人的にはうまく設計出来たと評価しています。
ただ、技術記事でよく見るClean Architectureとは若干異なる部分があるので、そこを深掘ります。
note
ソースコードはGo言語を使用しています。 本記事の内容がもしかしたら当てはまらない言語があるかもしれません。
その場合は許してください。
info
特定の技術記事を否定する意図はありません。
あくまで知見の共有が本記事の意図するところとなります。
この記事で伝えたいこと
Clean Architectureを採用するときに意識したら幸せになれたポイントを共有させていただきます。
解決したい課題
Clean Architectureを採用してみて、下記の課題感を感じました。 本記事では、下記の課題を深掘り、解決策の例を提示します。
- ソースコードが冗長になる
- ルールだらけの割にメリットを感じにくい
課題の原因
課題の原因はどこにあるかを考えると、実はClean Architectureが原因ではないことに気がつきました。
Clean Architectureが持つルールは、「ソースコードは、内側に向かってのみ依存できる」という依存の方向性のみのはずです。
レイヤーの命名ルールや、レイヤーの数のルールは存在しないはずです。
上記を踏まえて、原因はどこにあるのか考えてみました。
個人的には原因は「Clean Architectureの図を起因とする勘違い」と「技術駆動パッケージング」の掛け合わせと考えています。
1. 「Clean Architectureの図を起因とする勘違い」
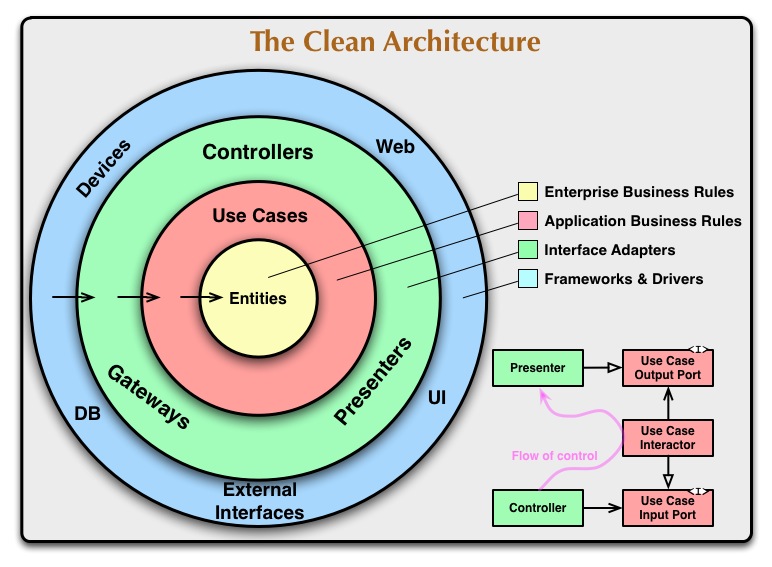 出展:The Clean Architecture
出展:The Clean Architecture
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
上記の図に引っ張られて、フレームワークのように解釈してしまいました。
概念を説明のための例でしかなく、上記の図そのものはルールではないことに注意したいです。
また、具体に注意を引かれてしまい、Clean ArchitectureはあくまでDDDの文脈であるという抽象を置き去りにしやすいと感じました。
2. 「技術駆動パッケージング」
技術駆動パッケージングとは、設計パターンや構造的に似ている者同士でフォルダ・パッケージ分けをする方法のことです。
出展:良いコード/悪いコードで学ぶ設計入門 ―保守しやすい 成長し続けるコードの書き方
https://www.amazon.co.jp/dp/4297127830
技術駆動パッケージングの例。
- UseCases
- AuthorUseCase
- ArticleUseCase
- Repositories
- AuthorRepository
- ArticleRepository
- Entities
- AuthorEntity
- ArticleEntity
ドメイン毎のパッケージングの例。
- Domain
- Author
- AuthorUseCase
- AuthorRepository
- AuthorEntity
- Article
- ArticleUseCase
- ArticleRepository
- ArticleEntity
課題を解決する技術、手法
上記を踏まえて、Clean Architectureを採用し設計する際に以下のことに注意しました。
また、go-clean-archリポジトリ を参考にしました。
- ルールは依存の方向のみ
- 外側の概念が内側の概念に依存するように設計する
- 依存性の逆転にはinterfaceを推奨するが、他の方法でも良い
- レイヤーはドメイン毎に粒度を変えて良い
- ドメインを表現するために下記の3層を基本とするが、各ドメイン毎に必須ではない
- Transport:Httpでの処理を担当する
- UseCase:ビジネスロジック
- Repository:DBへのアクセスを担当
- ドメインを表現するために下記の3層を基本とするが、各ドメイン毎に必須ではない
技術、手法の概要
下記のような設計を例にします。
- domain
- author.go
- article.go
- article
- transport
- article_service.go
- usecase
- article_usecase.go
- repository
- mysql
- article_repository.go
- author
- repository
- redis
- author_repository.go
domain/article.go
package domain
// Articleのデータを構造体で表現
type Article struct {
...
}
// ArticleUsecase をインターフェースで表現
type ArticleUsecase interface {
...
}
// ArticleRepository をインターフェースで表現
type ArticleRepository interface {
}
note
- domainパッケージを作成し、ドメインの構造体とレイヤーをインターフェースで表現する
- domain毎のパッケージを作成し、インターフェースを実装する
ArticleUseCaseはAuthorRepositoryのインターフェースに依存します。
ソースコードを書いてみるとしっくりきますが、依存の方向性のルールが守られることになります。
下記の例ですとdomain.ArticleRepositoryもしくはdomain.AuthorRepository の部分ですね。
article/usecase/article_usecase.go
import ".../domain"
func NewArticleUseCase(articleRepo domain.ArticleRepository, authorRepo domain.AuthorRepository) domain.ArticleUseCase{
...
}
技術、手法の効果
ドメインを確認すれば、関心毎がざっくりわかるようになる
domainを見に行くと、domainを表現するためのstructと、UseCaseとRepositoryのinterfaceが定義されています。
上記を合わせると、そのドメインがざっくりどのようなことをするのかを把握できます。
例えば、ArticleUseCaseにGetByIdという関数があれば、Articleを一件取得するユースーケースがあるんだなといった次第です。
ドメインを元に技術的な判断行うことができる
特定の処理や関数をutilに切り出すといった技術的な判断を、ドメインを元にして判断できるようになります。
例えば、関数AはArticleでも、Authorでも使用されているのでutilに切り出すとか、関数BはArticleでのみ使用されているのでutilに移す必要はないといった次第です。
課題がどう解決されるか
上記を踏まえると、ソースコードが冗長になるかどうかはClean Architectureは直接の原因になるわけではなく、設計者や実装者次第であると筆者は考えます。
Clean Architectureのルールの数についても、実は1つだけであるので、そのルールを守るためのHowはむしろ実装者に任せられているので、自由であるとも解釈できそうですね。
レイヤーの粒度はチームの人数や練度に応じて調整していくと良いと考えています。
その他
設計とは直接関係はありませんが、チーム構成や、プロジェクトの進め方もある程度影響すると考えます(コンウェイの法則)。
例えば、筆者の今のチームはユーザーストーリーベースで開発を進めているので、「ユーザーが体験する1つの価値」を実装することでチケットが完了となります。
そういった時に、タスクの分担としてUseCaseの担当といった技術的な境界面にフォーカスしてタスクをアサインすることはなく、ドメインそのものや、ドメインのデータフローが境界面になります。
どうしても技術駆動パッケージングになる場合は、一度チームや進め方を振り返ってみると、何かヒントになるかも知れません。

